
💪 Performance
| Rank | Base LLM | Agent System | Slow Think | Open Source | Avg. Score | Avg. Eff. | Avg. Steps | MC | CA | OA |
|---|---|---|---|---|---|---|---|---|---|---|
| 🏆 | Ph.D. Experts | Human | - | - | 83.50 | 75.48 | 6.52 | 81.05 | 81.75 | 85.51 |
| 1 | Gemini 2.5 Pro | Multi-Agent | Yes | No | 38.78 | 45.39 | 8.58 | 45.68 | 35.55 | 36.38 |
| 2 | OpenAI o4-mini-high | Multi-Agent | Yes | No | 37.37 | 43.41 | 8.30 | 42.48 | 34.90 | 34.59 |
| 3 | Claude Sonnet 4 | Multi-Agent | Yes | No | 36.73 | 39.13 | 8.92 | 42.76 | 34.76 | 34.85 |
| 4 | Gemini 2.5 Pro | Single-Agent | Yes | No | 36.10 | 41.20 | 9.81 | 40.36 | 34.81 | 35.39 |
| 5 | GPT-4.1 | Multi-Agent | No | No | 34.57 | 34.35 | 7.94 | 38.04 | 35.77 | 32.91 |
| 6 | Qwen3-235B-Thinking | Multi-Agent | Yes | Yes | 34.31 | 33.79 | 10.48 | 36.41 | 35.59 | 30.87 |
| 7 | Claude Sonnet 4 | Single-Agent | Yes | No | 34.18 | 37.34 | 9.55 | 38.92 | 34.07 | 33.05 |
| 8 | OpenAI o4-mini-high | Single-Agent | Yes | No | 33.93 | 35.12 | 10.63 | 41.46 | 35.86 | 32.88 |
| 9 | GLM-4.5 | Multi-Agent | Yes | Yes | 30.74 | 27.01 | 10.90 | 31.74 | 33.37 | 29.39 |
| 10 | GPT-4.1 | Single-Agent | No | No | 30.61 | 35.26 | 8.27 | 34.83 | 33.94 | 30.52 |
| 11 | Qwen3-235B-Thinking | Single-Agent | Yes | Yes | 29.97 | 31.21 | 10.20 | 33.41 | 34.41 | 28.90 |
| 12 | Claude 3.5 Sonnet | Multi-Agent | No | No | 29.34 | 23.67 | 8.16 | 30.99 | 33.72 | 28.88 |
| 13 | Qwen3-235B-Instruct | Multi-Agent | No | Yes | 28.83 | 38.13 | 7.82 | 31.99 | 31.86 | 28.67 |
| 14 | GLM-4.5 | Single-Agent | Yes | Yes | 27.17 | 25.13 | 11.82 | 29.30 | 30.91 | 27.29 |
| 15 | Kimi-K2-Instruct | Multi-Agent | No | Yes | 26.28 | 29.45 | 11.94 | 29.66 | 30.10 | 25.58 |
| 16 | Claude 3.5 Sonnet | Single-Agent | No | No | 24.62 | 21.98 | 7.89 | 28.90 | 28.35 | 24.52 |
| 17 | Qwen3-235B-Instruct | Single-Agent | No | Yes | 23.47 | 36.85 | 7.24 | 26.83 | 27.54 | 23.05 |
| 18 | Kimi-K2-Instruct | Single-Agent | No | Yes | 22.32 | 23.57 | 12.86 | 26.27 | 25.91 | 22.29 |
Table 1: LLM-based Agents Performance on PaperArena-Hub. Multi-Agent systems are highlighted with green background.
MC = Multiple Choice, CA = Concise Answer, OA = Open Answer (average scores across Easy, Medium, and Hard difficulties).
Key Findings: Gemini 2.5 Pro (Multi-Agent) achieves the highest overall performance among LLM-based agents at 38.78%, yet a substantial gap persists with the Ph.D. expert baseline at 83.50%. Agent accuracy consistently degrades with increased task difficulty and on open-ended formats. Generally, closed-source and "slow-thinking" LLMs outperform their counterparts. While multi-agent systems enhance both accuracy and efficiency, most agents demonstrate inefficient planning by invoking far more tools than necessary. This inefficiency highlights fundamental limitations in their multi-step reasoning and tool execution control.
📖 Abstract
Existing benchmarks inadequately test LLM agents on realistic scientific tasks. We introduce PaperArena, a new evaluation benchmark where agents must address complex research questions by reasoning across multiple papers and using tools. Our platform provides agents with tools for parsing, retrieval, and computation to synthesize well-grounded answers. Experiments reveal that even advanced agents achieve only 38.78% average accuracy and exhibit inefficient tool usage. PaperArena offers a crucial platform for developing more capable agents for scientific discovery.
✨ Motivation

Figure 1: Motivation of the PaperArena benchmark.
⚙️ Key Features
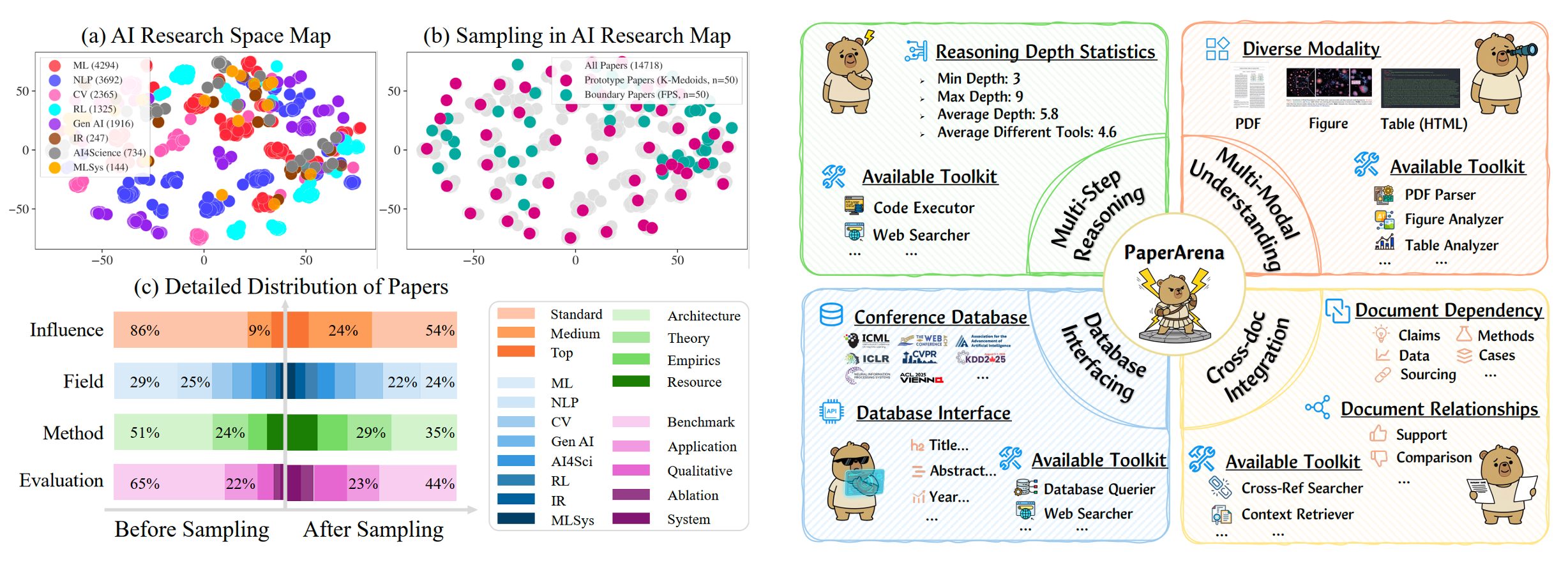
Figure 2: Overview of the PaperArena Features.
📊 Multi-Step Reasoning
PaperArena evaluates agents on multi-step reasoning that simulates scientific workflows. Tasks require the sequential use of tools, such as PDF parsers, context retrieval, and web search, to trace claims and validate results.
🖼️ Multi-Modal Understanding
PaperArena assesses multimodal understanding by requiring agents to reason over text, figures, tables, and equations. Tasks involve aligning visual data with textual claims or comparing chart trends to tabular metrics.
📚 Cross-Document Integration
PaperArena evaluates cross-document integration by requiring agents to synthesize information from multiple papers. Tasks include verifying a claim against a cited work or retrieving implementation details from another document.
🗄️ Database Interfacing
PaperArena tests an agent's ability to interface with a structured paper database. Agents must formulate precise queries for metadata, interpret the returned results, and incorporate the retrieved evidence into their reasoning steps.
🌟 Benchmark Construction
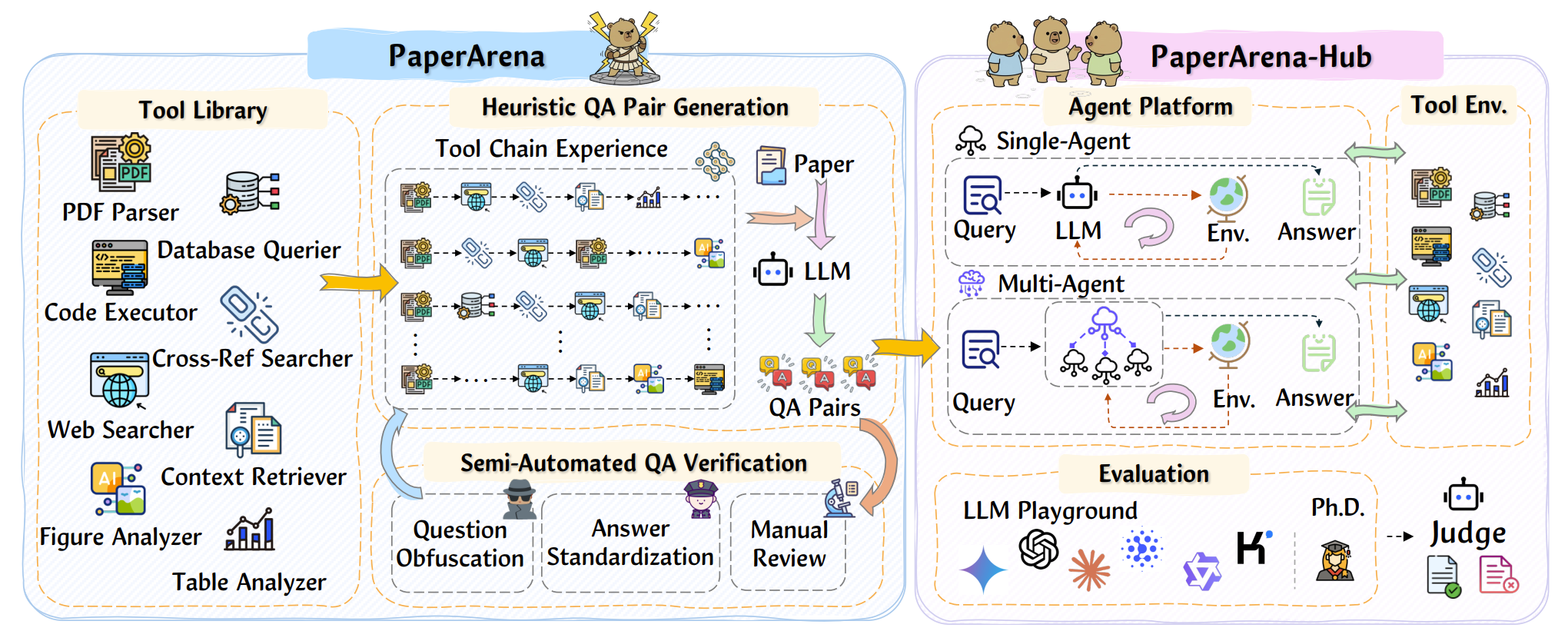
Figure 3: Pipeline of the PaperArena Construction and PaperArena-Hub Implementation.
The figure above illustrates the comprehensive pipeline for the construction of the PaperArena benchmark and the implementation of its evaluation platform, PaperArena-Hub.
- On the left, the PaperArena construction process details a tool-centric pipeline for generating question-answer (QA) pairs. It begins with a Tool Library and predefined Tool Chain Experience guiding a Large Language Model (LLM) to create initial QA pairs from scientific papers. These pairs then undergo a Semi-Automated QA Verification stage—including question obfuscation, answer standardization, and manual review—to ensure high quality and difficulty.
- On the right, the PaperArena-Hub platform serves as a modular framework for agent evaluation. It features an Agent Platform that supports both Single-Agent and Multi-Agent systems. When given a query, the agent's LLM interacts with the Tool Environment to generate an answer. The final answer is then assessed in the Evaluation module, where a Judge (typically a powerful LLM) scores its performance against a human Ph.D. expert baseline.
🔖 BibTeX
@inproceedings{wang2025paperarena,
title={PaperArena: An Evaluation Benchmark for Tool-Augmented Agentic Reasoning on Scientific Literature},
author={Daoyu Wang, Mingyue Cheng, Qi Liu, Shuo Yu, Zirui Liu, Ze Guo},
year={2025},
eprint={2510.10909},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2510.10909}
}